Zatem chcesz się nauczyć programowania pod Windows… Dzięki tej serii tutoriali dowiesz się wszystkiego, co jest niezbędne aby wejść we wspaniały świat kodowania – świat małych i szybkich programów, które uruchomią się na każdym komputerze. Świat, w którym wszystko jest możliwe…
Co jest potrzebne?
- Macro Assembler 32 pod Windows – można znaleźć w sieci, plik nazywa się masm32v7.zip – poszukaj na google, na pewno znajdziesz.
- Windows
- Win32 Programmer’s Reference – czyli plik pomocy zawierający opisy wszystkich najpotrzebniejszych funkcji API – rzecz właściwie niezbędna, jest on dołączany do różnych pakietów programistycznych np. do Delphi 5, na pewno można również pobrać ze strony Microsoftu.
- Jakiś edytor tekstu – właściwie wystarczy zwykły notatnik lub Quick Editor dołączany do MASM, jednak z czasem radziłbym zaopatrzyć się w potężniejsze narzędzie, na przykład Ultra Edit.
Co się może przydać?
- Pojęcie o binarnym (dwójkowym) i szesnastkowym systemie liczbowym
- Disasembler/Debugger (na pewno jest na stronach crackerskich, polecam SoftIce)
- Znajomość podstaw Assemblera
Dlaczego właśnie Assembler?
Ludzie, którzy znają sie już trochę na rzeczy i programowali w innych językach, zaraz zapytają: Po co się męczyć? Przecież każdy współczesny kompilator wysokiego poziomu ma wbudowaną optymalizację, obsługę wyjątków, debuggera itp., natomiast programowania w assemblerze bardzo trudno jest się nauczyć, a kod jest mało czytelny.
Jeśli chodzi o debugger, to używanie SoftIce’a daje nawet większe możliwości niż jakikolwiek wbudowany moduł w Delphi, VC i podobnych, ze względu na to, że pracuje na niskim poziomie, a więc daje bezpośredni dostęp do rejestrów, pamięci i kodu. Natomiast jeśli chodzi o wyjątki, to Windows ma własną ich obsługę, która we współpracy z SoftIce pozwala dokładnie „namierzyć” miejsce wystąpienia błędu. A optymalizacja? Nie wierzę w to, że jakikolwiek automat dorówna ludzkiemu umysłowi. Poza tym wystarczy porównać rozmiary programów skompilowanych w Delphi i Assemblerze, które wyświetlają tylko puste okno – program napisany w Delphi może być nawet 300 razy większy.
Czy programowania w Assemblerze trudno jest się nauczyć? Moim zdaniem na pewno nie jest to dużo trudniejsze od nauki np. C. Oczywiście w tej dziedzinie nic nie dorówna Visual Basicowi, jednak możliwości tego ostatniego są mocno ograniczone. A jeśli chodzi o czytelność kodu – dawno już minęły czasy DOSu, kiedy trzeba było się zastanawiać co oznacza numerek przy instrukcji int. Teraz, dzięki funkjom API, programy assemblerowe nie ustępują czytelnością C++, a nawet go przewyższają. Sądzę, że łatwiej jest zrozumieć instrukcje wykonywane krok po kroku niż wiele warstw zagnieżdżonych funkcji, z jakimi mamy do czynienia w C. Zresztą, w każdym języku programowania komentowanie jest bardzo ważne. Jeśli będziesz stosował komentarze w swoim kodzie, na pewno nie zginiesz i zawsze będziesz wiedział do czego służą poszczególne polecenia.
Rejestry procesora
Co to jest rejestr? Jest to mała komórka pamięci umieszczona przy procesorze w celu bardzo szybkiego dostępu. Operacje na rejestrach trwają o wiele krócej niż te same operacje wykonywane na zmiennych w pamięci. Każdy 32-bitowy procesor posiada rejestry 32-bitowe (czyli 4-bajtowe), które dzielą się na 16-bitowe, a te z kolei na 8-bitowe (aczkolwiek nie wszystkie). W rejestrach ośmiobitowych można zapisać tylko jeden bajt, a więc liczby od 0 do 255, 16-bitowych – od 0 do 65 535, a w 32-bitowych – od 0 do 4 294 967 295.
Rejestry danych (ogólnego przeznaczenia)
Zasadniczo rejestry danych są cztery (EAX, EBX, ECX, EDX), ale – jak pisałem wyżej – można je jeszcze podzielić. Na poniższym rysunku znajdują się nazwy i rozmiary wszystkich rejestrów danych:
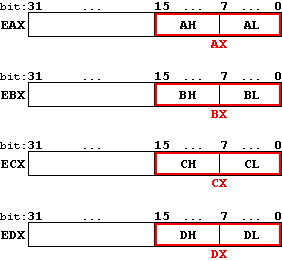
Czyli, jak widać, mniej znacząca połowa rejestru EAX nosi nazwę AX, a AX dzieli się na AH i AL. Podobnie jest z rejestrami EBX, ECX i EDX.
Rejestry indeksowe
Czyli EDI i ESI (dzielą się jeszcze na DI i SI, podobnie jak przy rejestrach danych) stosuje się przy operacjach na ciągach (ang. string – zbiór bajtów zawierający np. jakiś tekst) oraz jako rejestry ogólnego przeznaczenia. Warto zaznaczyć, że Windows używa ich do swoich celów i zmiania ich zawartości może spowodować (znany wszystkim skądinąd) komunikat „Program wykonał…”. Dlatego też po każdej modyfikacji tych rejestrów należy przywrócić ich poprzednią wartość.
Pozostałe rejestry
Poza wymienionymi wyżej rejestrami, procesor zawiera jeszcze rejestry EBP i ESP, które są używane przy operacjach związanych ze stosem (o stosie czytaj niżej, przy opisie instrukcji PUSH i POP), oraz EIP, który zawsze zawiera adres w pamięci do aktualnie wykonywanej instrukcji (tego rejestru nie da się bezpośrednio modyfikować, więc nie jest on w ogóle dostępny w Macro Assemblerze).
Podstawowe instrukcje
MOV
Bez wątpienia instrukcja MOV jest najczęściej stosowaną instrukcją assemblera. Służy ona do nadawania wartości zmiennym oraz rejestrom. Na przykład, aby umieścić w rejestrze eax liczbę 12345, piszemy:
mov eax,12345
Podobnie jest ze zmiennymi:
mov zmienna,12345
Można również spowodować, aby eax przyjął wartość innego rejestru, np. ebx lub zmiennej:
mov eax,ebx mov eax,zmienna
Bardzo ciekawy jest następujący zapis:
mov eax,dword ptr [ebx]
Powoduje on umieszczenie w eax liczby, która znajduje się pod adresem wskazywanym przez ebx. Oznacza to, że w ebx znajduje się adres jakiejś wartości w pamięci, a eax przyjmuje tą wartość. Operator dword mówi procesorowi ile bajtów z pamięci umieścić w eax: dword – 4 bajty, word – 2 bajty, byte – 1 bajt. Oczywiście niewłaściwy będzie zapis:
mov eax,byte ptr [ebx]
ponieważ rejestry 32-bitowe przyjmują tylko i wyłącznie dane zapisane w postaci czterech bajtów. Aby umieścić w rejestrze bajt z pamięci, musimy posłużyć się mniejszym rejestrem, np. al:
mov al,byte ptr [ebx]
Nieprawidłowy jest również zapis:
mov zmienna1, zmienna2
Aby nadać zmiennej wartość innej zmiennej, posługujemy się rejestrem pomocniczym:
mov eax,zmienna2 mov zmienna1,eax
ADD i SUB
Jak można się domyślić, instrukcja add służy do dodawania, natomiast sub – do odejmowania. Oto kilka przykładów:
add eax,10 sub eax,ebx add zmienna, -100
Pierwsza instrukcja spowoduje dodanie liczby 10 do liczby znajdującej się w rejestrze eax i zapisanie wyniku do eax (eax=eax+10). Druga – odjęcie ebx od eax (eax=eax-ebx), natomiast trzecia – dodanie -100 do zmiennej (czyli odjęcie 100; zmienna=zmienna+(-100)).
MUL i DIV
Te dwie instrukcje wykonują odpowiednio: mnożenie i dzielenie. Niestety, tutaj sprawa nie jest aż tak prosta jak z odejmowaniem i dodawaniem. Oto przykład mnożenia:
mov eax,10 mov ecx,50 mul ecx
Powyższe instrukcje wykonują mnożenie 10 przez 50. Najpierw w eax umieszczana jest liczba 10, czyli pierwszy czynnik. Następnie w ecx ląduje drugi, czyli 50. Eax jest zawsze domyślnym czynnikiem, aby wykonać mnożenie musimy w instrukcji mul wskazać drugi (może to być dowolny rejestr, u nas – ecx). A zatem polecenie mul ecx pomnoży rejestr eax przez ecx i umieści wynik w eax:edx (taki zapis oznacza, że jeżeli wynik nie zmieści się w eax, pozostała jego część znajdzie się w edx).
mov eax,50 mov ecx,10 sub edx,edx div ecx
Z dzieleniem jest podobnie, to znaczy dzielną umieszczamy w eax, a dzielnik w dowolnym rejestrze (który podajemy jako parametr instrukcji div). Dodatkowo musimy jeszcze wyzerować rejestr edx – robimy to poprzez odjęcie jego samego od siebie (edx=edx-edx). Po wykonaniu dzielenia, wynik zostanie umieszczony w eax, natomiast ewentualna reszta – w edx.
PUSH i POP
Zanim przejdziemy do omawiania tych dwóch instrukcji, musimy dowiedzieć się co to jest stos. Stos jest to pewien obszar pamięci, który możemy używać jako miejsce do tymczasowego przechowywania potrzebnych nam wartości (liczb). Aby lepiej to zrozumieć, wyobraźcie sobie stosik kartek, z jakąś liczbą zapisaną na każdej z nich. Instrukcja push działa w ten sposób, że bierze nową kartkę, zapisuje na niej podaną przez nas wartość i kładzie na górę stosu. Natomiast pop zdejmuje kartkę ze stosu, odczytuje z niej liczbe i umieszcza ją we wskazanej przez nas zmiennej lub rejestrze. Widać więc, że w danej chwili mamy dostęp tylko i wyłącznie do kartki, która leży na górze stosu, nie możemy wyjąć kartki ze środka kupki (można to ograniczenie obejść, ale o tym innym razem). Popatrzmy zatem jak działają te instrukcje:
push 10 pop eax
Push umieszcza na stosie liczbę 10, która jest następnie zdejmowana za pomocą instrukcji pop i umieszczana w rejestrze eax.
Zakończenie
Niestety, ten odcinek był czysto teoretyczny, ale pierwszy program, wyświetlający okienko z komunikatem, napiszemy już w kolejnym.
zacząłem czytać i po prostu wciąga…jest przystępnie napisane…pozdrawiam..
fajny miły wstęp.
Wstep jest miły i pewnie jest po tyo żeby nie ostraszasz od asma,ale zieloni zaczynajacy z nim swoją "przygode" powini wiedzieć więcej na temat rejestrów wywołań czy segmatancji lub liniowości pamięci ram…
Wstep jest miły i pewnie jest po tyo żeby nie ostraszasz od asma,ale zieloni zaczynajacy z nim swoją "przygode" powini wiedzieć więcej na temat rejestrów wywołań czy segmatancji lub liniowości pamięci ram…
Jestem pod wrażeniem. Kurs jest bardzo jasno napisany. Asembler dzięki takim tekstom coraz bardziej mnie wciąga.
Jestem pod wrażeniem. Kurs jest bardzo jasno napisany. Asembler dzięki takim tekstom coraz bardziej mnie wciąga.
po prostu genialny
po prostu genialny
Świetny!
I want more! :D
Świetny!
I want more! :D
świetny artykuł a jaki przydatny dla studentów;p
lepszy niż tan na 1lo tarnow
dzięki, wyjaśniłeś mi kilka rzeczy, które mnie zastanawiały z podstaw ;)
dzięki, wyjaśniłeś mi kilka rzeczy, które mnie zastanawiały z podstaw ;)
Świetny kurs , zapraszam na http://www.darmowy-cms.pl
Świetny kurs , zapraszam na http://www.darmowy-cms.pl
dobry poczatek
sla mnie bomba !!!
sla mnie bomba !!!
Najlepszy tutorial o asm jaki znalazłem na sieci! Proszę kontynuaować!
co szukalem, dzieki
Bardzo ciekawy artykuł. Zapraszam Cię na moją stronę o podobnej tematyce: http://0dfh.opx.pl/
Kurs „Podstawy assemblera”, a parę linijek niżej „co się może przydać” podstawy assemblera…
to mi wystarczy żeby stąd wyjść poprostu bezsensu…